

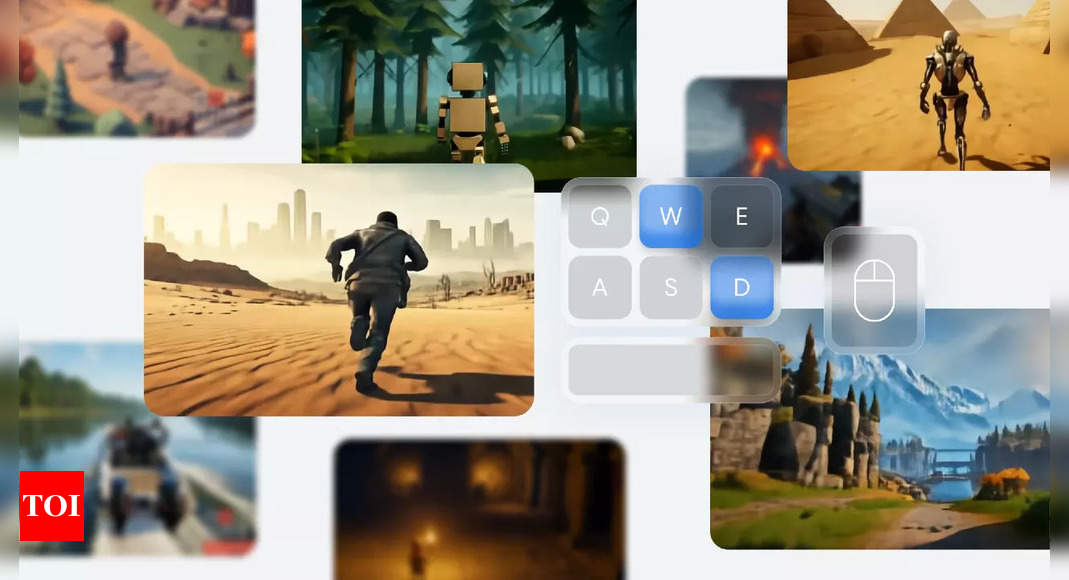
Google DeepMind launched Genius 2yr You could have a mannequin in a position to generate various and interactive 3D environments from a single immediate picture. These environments can be utilized in video games, animated films, and coaching embedded AI brokers.
Genie 2 builds on its predecessor, Genie 1, which centered on 2D world technology. This new iteration expands into 3D, creating wealthy and dynamic digital worlds that may be explored and interacted with.
“Genie 2 may enable future brokers to be skilled and evaluated in an infinite program of latest worlds. Our analysis additionally paves the way in which for brand spanking new and artistic workflows for prototyping interactive experiences,” stated Google DeepMind.
Key Capabilities of Genie 2
Google DeepMind shared a whole lot of use circumstances of this AI mannequin, together with:
Various 3D World Era: From a single picture, Genie 2 can generate all kinds of 3D environments, full with objects, characters and interactive parts.
Motion controllability: Customers can work together with these worlds utilizing keyboard and mouse inputs, permitting human or AI brokers to navigate and manipulate the setting.
Rising capabilities: Genie 2 options rising capabilities, together with object interactions, character animation, physics simulation, and the flexibility to foretell the habits of different brokers within the setting.
Lengthy-term consistency: The mannequin can preserve fixed world states for as much as a minute, producing new and believable content material on the fly. Genie 2 also can generate environments from numerous views, together with first-person, isometric, and third-person views.
Google DeepMind says Genie 2 is an autoregressive latent diffusion mannequin that was “skilled on a big video dataset. After passing by means of an autoencoder, the latent frames from the video are fed to a big transformer dynamics mannequin skilled with a causal masks just like that utilized by giant language fashions.”