

Web is a important supply of data for folks to search for points associated to well being. [1]. Nonetheless, on-line well being data is blended high quality, which regularly incorporates faulty data that requires data customers to judge and decide their high quality. [2]. Addressing the prevalence of faulty on-line well being data is essential to safeguard public well being and be certain that folks can entry dependable and dependable data to make knowledgeable selections about their well being [3].
The faulty data or low high quality well being data prevails in lots of well being domains, starting from infectious ailments (COVID-19, Ebola), persistent situations (most cancers, diabetes), life-style (meals and vitamins) [4]. The faulty data of well being and low high quality data can contribute to a myriad of antagonistic outcomes, together with the adoption of dangerous practices [5]The rejection of confirmed medical interventions [6]and the exacerbation of current well being disparities [7]. As well as, faulty data can erode belief in licensed sources [8]undermining efforts to disseminate exact data and promote proof -based practices. As well as, susceptible populations, corresponding to these with digital literacy and boundaries of restricted digital linguistics, or underrepresented communities, are significantly vulnerable to the results of faulty well being data, additional increasing well being inequalities. [9]. Whereas well being professionals can take part within the correction of faulty data, their skill is troublesome to climb to prevalence and continuously evolving the faulty data of well being. In consequence, there’s a rising want for automated instruments to judge the standard of well being information on scale to make sure that customers are outfitted with exact and dependable data.
Synthetic intelligence (AI) is a promising software to facilitate the speedy dissemination of data to confirm details by automating the claims verification course of and offering customers with exact and up to date data [10]. As well as, in comparison with skilled occasions verifiers, journalists and licensed entities which can be typically perceived as conventional approaches, the verification of faulty data primarily based on AI can function a quicker, quicker, scalable and probably neutral software to establish false data on varied platforms. By profiting from synthetic intelligence applied sciences, public well being authorities, researchers and know-how corporations can collectively develop scalable options to detect and deal with faulty well being data, in the end promote well being literacy and practice folks to make knowledgeable selections about their well being.
Present research on the classification of faulty data and the analysis of data high quality may be categorised into two common approaches: primarily based on veracity and primarily based on standards [11]. Veracity -based approaches deal with evaluating the target precision of well being -related claims by means of cross -inable reference [12,13,14,15]. For instance, Meppelink et al. [13] Utilized automated classification methods to investigate internet pages associated to vaccines, figuring out that the knowledge is dependable if they’re aligned with licensed pointers. Quite the opposite, standards -based approaches deal with evaluating the standard of well being data by means of the usage of predefined metrics, such because the credibility of the supply, with out essentially verifying the precision of particular person claims. [16,17,18]. Each strategies are important however differ within the strategy: veracity -based approaches consider authenticity, whereas standards -based approaches consider content material high quality. Standards -based approaches can present data customers with extra granular and detailed concepts past dichotomized authenticity and can even domesticate capability amongst data customers to discern low high quality well being data.
Along with exactly qualifying the standard and validity of well being data, it’s also important to offer related and acceptable explanations to the qualification. The prevailing literature highlights the significance of offering clear explanations to advertise confidence in selections generated by AI, significantly in reality verification functions [19,20,21,22,23]. Data customers count on not solely veracity labels but in addition clear and persuasive explanations. Nonetheless, most AI fashions created for the analysis of well being content material fall brief to offer this stage of transparency. Present fashions that declare to be explainable, as demonstrated within the work of Ayoub et, al. [24] typically trusts impartial interpretable computerized studying strategies corresponding to Lima [25] or tray [26]They deal with explaining how particular traits affect predictions. Whereas these instruments present data on the mannequin’s resolution -making course of, they typically don’t present readable explanations associated to the context that entice lay folks. This underlines the necessity to transcend merely explaining the selections of the mannequin, to make sure that explanations assist customers to raised perceive the justification concerned within the analysis of well being data.
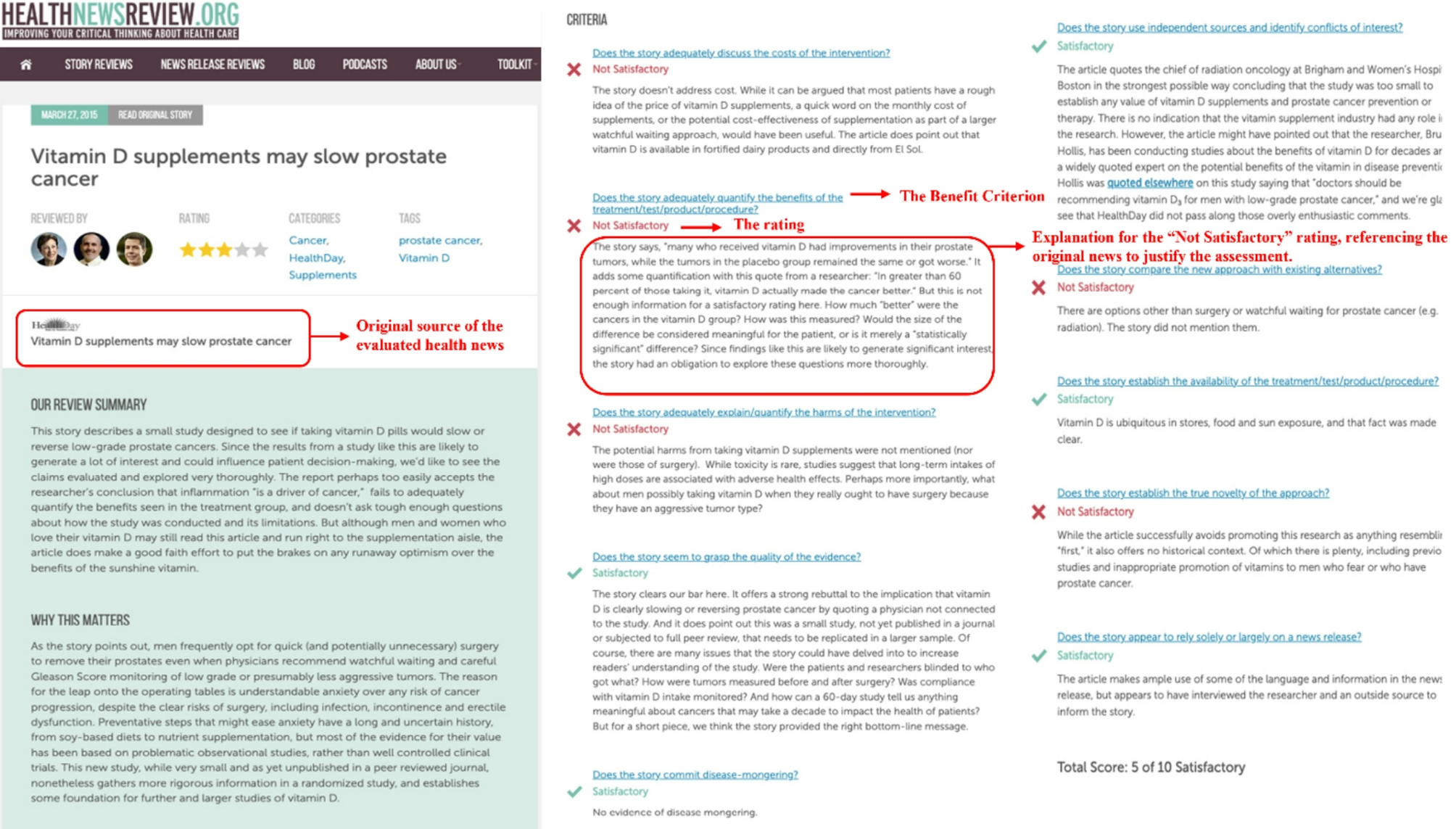
Beforehand skilled generative transformer (GPT), a complicated LLM developed by OpenAI, has acquired rising consideration as a consequence of its skill to take part in conversations much like people and promising efficiency in a number of domains [27, 28]. Predrah within the huge web information of the true world, GPT is properly positioned to investigate and detect on-line textual content patterns corresponding to well being information and supply customers legible to customers. Present research have examined GPT efficiency in identification and response to faulty well being data [27, 29]However these evaluations have usually targeted on temporary claims or well being myths. Equally, Luo et al. [30] He evaluated the precision, effectiveness, legibility and applicability of GPT-Four and Ernie in 20 rumors of well being. Choi et al. [31] Evaluated whether or not the LLMs beforehand skilled and adjusted can match the claims made in social media publications associated to COVID with claims beforehand managed by details. These research supplied a wealthy data on the viability of the LLM to judge the standard of well being data. Nonetheless, so far as we all know, there is no such thing as a examine that evaluates LLM’s skill to judge the standard of well being data by means of predefined standards which can be broadly adopted by consultants in verification of human details. This analysis is essential, since it may well reveal all through which standards can fall brief and want extra adjustment. As well as, it lacks a scientific analysis of GPT and different LLM within the context of extra advanced well being narratives, corresponding to full reviews of the well being media that embrace descriptions of medical interventions, which higher signify the well being data that the laity devour, in comparison with the information units cured by consultants. As well as, few research have used structured analysis frameworks validated, and there was restricted investigation into the flexibility to clarify its explainability in an accessible and comprehensible method for the lay public.
To handle these gaps, this examine evaluates the potential of GPT-Three.5-Turbo, a consultant and broadly used LLM, to judge the standard of well being information articles utilizing rigorous and predefined standards. The examine additionally used blended strategies to judge linguistic complexity, readability and high quality of explanations offered by GPT-Three.5-Turbo. This examine goals to find out how properly LLM can replicate the method of analysis of human consultants used within the analysis of well being information high quality, which means offering a numerical ranking and pure language explanations for qualifications.